
Clusters LVS + Keepalived en Linux
Otra opción para instalar un cluster HA (High Availability, alta disponibilidad), utilizados principalmente en granjas de servidores, es LVS junto con KeepAlived (keepalived.org) que se encarga de monitorizar los balanceadores de carga (mediante el protocolo VRRP, Virtual Router Redundancy Protocol) y los servidores reales (permite chequeos TCP_CHECK, HTTP_GET y SSL_GET), reemplazando así a HeartBeat y Ldirectord, las herramientas utilizadas en UltraMonkey.
Recursos
- The Keepalived solution: linuxvirtualserver.org/docs/ha/keepalived.html
Veamos un ejemplo de un cluster HA utilizando LVS + Keepalived:
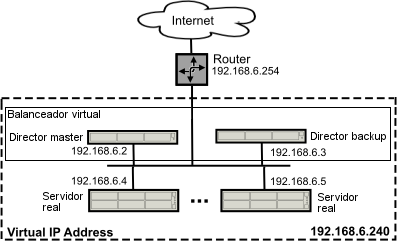
- instalar KeepAlived (paquete keepalived)
- /etc/keepalived/keepalived.conf (en el master): el archivo de configuración
de KeepAlived tiene tres secciones:
- global_defs: directivas globales:
global_defs { notification_email { [email protected] } notification_email_from [email protected] smtp_server 127.0.0.1 smtp_connect_timeout 30 lvs_id LVS_EXAMPLE_01 }
- notification_email: quién recibe el email de alerta.
- notification_email_from: remite del email de alerta.
- lvs_id: identificador del director.
- virtual_server: directivas de cada servidor virtual. Por ejemplo, para un servidor web
en la IP virtual 192.168.6.240, puerto 80:
virtual_server 192.168.6.240 80 { delay_loop 30 lb_algo wrr lb_kind NAT persistence_timeout 50 protocol TCP sorry_server 192.168.6.2 80 real_server 192.168.6.4 80 { weight 2 TCP_CHECK { connect_port 80 connect_timeout 3 } } real_server 192.168.6.5 80 { weight 1 TCP_CHECK { connect_port 80 connect_timeout 3 } } }
- sorry_server: servidor que se añdirá al pool si todos los servidores reales fallan.
- real_server: servidor real perteneciente al pool.
- weight: peso relativo del servidor para balancear la carga.
- TCP_CHECK: método para chequear la disponibilidad del servidor.
Si tenemos más IPs virtuales o servicios añadiremos otras secciones virtual_server: por ejemplo, en la misma IP virtual 192.168.6.240 un servidor de correo en el puerto 25:
virtual_server 192.168.6.240 25 { delay_loop 15 lb_algo wlc lb_kind NAT persistence_timeout 50 protocol TCP sorry_server 192.168.6.2 25 real_server 192.168.6.6 25 { weight 1 TCP_CHECK { connect_port 25 connect_timeout 3 } } real_server 192.168.6.7 25 { weight 2 TCP_CHECK { connect_port 25 connect_timeout 3 } } }
- vrrp_instance: directivas para monitorizar los directores:
vrrp_instance VI_1 { state MASTER interface eth0 lvs_sync_daemon_inteface eth0 virtual_router_id 51 priority 150 advert_int 1 smtp_alert authentication { auth_type PASS auth_pass example } virtual_ipaddress { 192.168.6.240 } }
- state: MASTER o BACKUP.
- priority: el master debe tener mayor priority.
- global_defs: directivas globales:
- /etc/keepalived/keepalived.conf (en el backup): el archivo de configuración
de KeepAlived en el backup es casi igual al del master, sólo se diferencia en tres directivas:
- lvs_id: LVS_EXAMPLE_02, el identificador debe ser diferente.
- priority: 100, inferior a la del master.
- states: BACKUP.
- Arrancar y comprobar
- arrancar KeepAlived: en ambos directores:
# /etc/init.d/keepalived start Starting Keepalived for LVS: [ OK ]
- comprobar la IP virtual:
# ip addr sh eth0 - comprobar LVS:
# ipvsadm -L -n - comprobar la sincronización LVS:
# /etc/ha.d/resource.d/LVSSyncDaemonSwap master status - simular el fallo de Apache
# /etc/init.d/apache stop - simular el fallo del director master:
# /etc/init.d/keepalived stop - simular que el director master vuelve a estar en línea:
# /etc/init.d/heartbeat start - logs: KeepAlived envía logs a /var/log/messages.
- arrancar KeepAlived: en ambos directores:
8 Comentarios en “Clusters LVS + Keepalived en Linux”
Deja un comentario
Buenas,
hay una cosa que no entiendo, si estamos en una red 192.168.6/24, porqué en la definición del virtual server el parámetro lb_kind es ‘NAT’ y no ‘DR’?
es posible que el director sean los dos master?
pipen, el balanceador de carga o director es un sistema activo-pasivo, sólo trabaja uno de ellos. El balanceador backup sólo estará on-line si falla el master.
Hola, muchas gracias por el aporte.
Solo quería hacer un comentario relativo al envío de los mails, cuando un servidor backup para a ser master envía el correo, pero cuando el master vuelve a estar el línea, no me notifica por mail, solo me envía el mail cuando reinicio el servicio keepalived.
Sabes que puede estar ocurriendo?
gx, Roger.
esta informacion es muy buena, pero aun sigo sin poder utilizar keepalived bueno aunke yo estoy con conntrackd con ese fin estoy buscando informacion de keepalived
Hola!
Se puede hacer que haya varios directores de backup y que las peticiones se las balanceen entre ellos?? Es decir que los servidores reales sean servidores de backup y estén todos dentro de la IPV, que sea una red todos sean servidores reales, uno de ellos balancee la carga entre el y los demás y que si este cae, otro de los servidores reales sea el que haga la función de balanceo??
Lo unico que no entiendo es como armar la red fisicamente o como se tiene que instalar……. el cableado y los cpu’s disculpen por meterme en camisas de once varas pero en mi escuela ya saben solo piden y no enseñan jejeje todo se lo dejan a uno solo…………………………. Solo me dijeron arma un cluster
Buenas,
Llevo siguiéndote desde hace un tiempo. Si no recuerdo mal publicaste un artículo sobre el DRBD fantástico y ahora te lo has currado mucho con el tema de los balanceadores de carga.
Te felicito.
Saludos!